29/11/2021
En el entorno digital, la representación de caracteres es fundamental. Entender cómo se codifican las letras, especialmente las minúsculas acentuadas, es crucial para la correcta visualización y manipulación de textos. Este artículo explora el código ASCII, su relación con las minúsculas acentuadas y las diferencias con otros sistemas de codificación como Unicode.
¿Qué es ASCII?
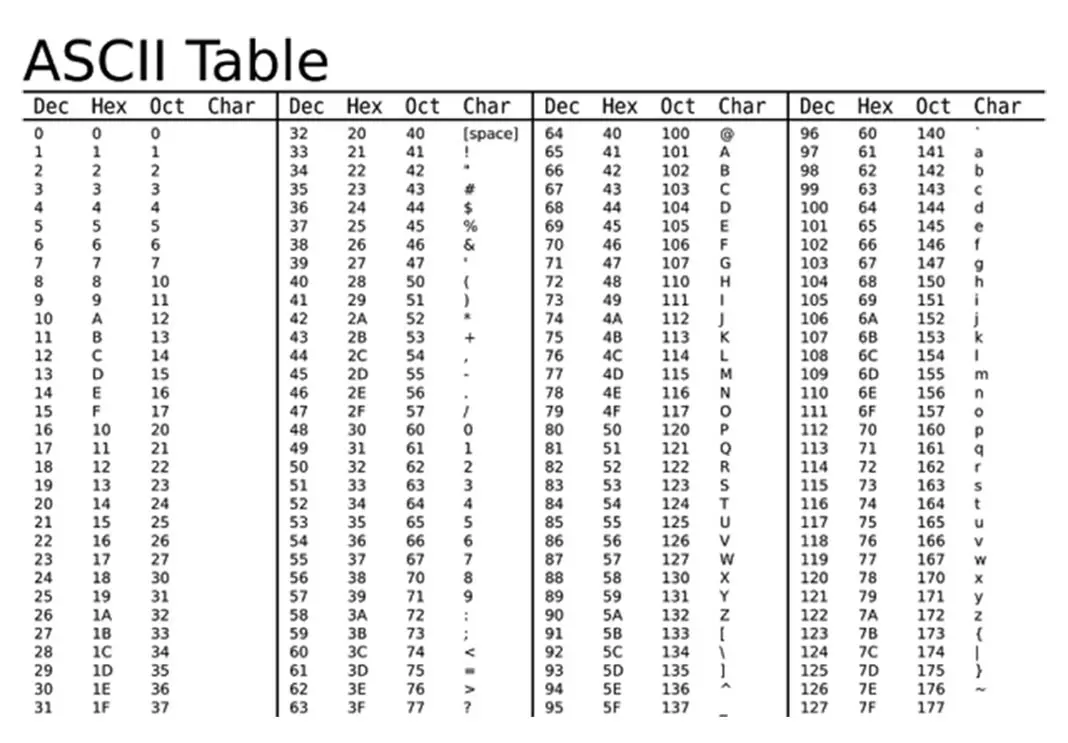
ASCII (American Standard Code for Information Interchange) es un estándar de codificación de caracteres utilizado en telecomunicaciones. Es un código de siete bits que, originalmente, representaba 128 caracteres: letras mayúsculas y minúsculas del alfabeto inglés, números, símbolos de puntuación y caracteres de control. Aunque se creó para el inglés, su influencia perdura en la actualidad.
La limitación de siete bits implica que solo puede representar 128 caracteres. Esta restricción se superó con el desarrollo de extensiones de ASCII, como el Extended ASCII (128-255), que incorporaron caracteres adicionales, incluyendo algunos acentos. Sin embargo, la representación de caracteres con acentos en ASCII sigue siendo inconsistente y dependiente de la codificación utilizada (por ejemplo, ISO-8859-1 o Windows-1252).
ASCII y las Minúsculas Acentuadas
El código ASCII original no incluía caracteres acentuados. Para representar estas letras, se recurrió a las extensiones ASCII, pero la codificación exacta variaba según el sistema operativo y la región. Esto conllevaba problemas de compatibilidad entre diferentes sistemas.
Por ejemplo, la letra 'á' no tiene un único código ASCII. Su representación depende del juego de caracteres utilizado. En Windows-1252, su valor decimal es 225, mientras que en otras codificaciones podría ser diferente. Esta falta de uniformidad dificultaba el intercambio de información entre sistemas.
| Carácter | Windows-1252 (Decimal) | ISO-8859-1 (Decimal) |
|---|---|---|
| á | 225 | 225 |
| é | 233 | 233 |
| í | 237 | 237 |
| ó | 243 | 243 |
| ú | 250 | 250 |
| ü | 252 | 252 |
Nota: La tabla muestra algunos ejemplos. Existen otros caracteres acentuados con diferentes valores ASCII según la codificación utilizada. La inconsistencia se debe a la naturaleza de las extensiones de ASCII que no fueron estandarizadas globalmente.

La Necesidad de Unicode
La falta de estandarización en la representación de caracteres acentuados en ASCII llevó al desarrollo de Unicode, un estándar de codificación de caracteres mucho más amplio y universal. Unicode asigna un código único a prácticamente cualquier carácter de cualquier idioma, incluyendo todos los tipos de minúsculas acentuadas.
Unicode resuelve el problema de incompatibilidad entre sistemas. Al usar Unicode, se garantiza que un mismo texto se mostrará correctamente en diferentes sistemas operativos, aplicaciones y navegadores, independientemente de la región o la configuración.
Comparativa ASCII vs. Unicode
| Característica | ASCII | Unicode |
|---|---|---|
| Número de caracteres | 128 (original), 256 (extendido) | Más de 14000 |
| Soporte de idiomas | Principalmente inglés | Soporte para la mayoría de los idiomas del entorno |
| Compatibilidad | Limitada, problemas con caracteres especiales | Alta compatibilidad entre sistemas |
| Estandarización | Parcial, extensiones no universalmente estandarizadas | Estandarizado globalmente |
| Representación de minúsculas acentuadas | Dependiente de la codificación extendida utilizada | Representación consistente y única para cada carácter |
Consultas Frecuentes sobre A Imprenta Minúscula Acentuada ASCII
A continuación, se responden algunas consultas frecuentes:
- ¿Cuál es el valor ASCII de la 'a' minúscula sin acentos? Su valor ASCII es 9
- ¿Cómo se representan las minúsculas acentuadas en ASCII? Depende de la codificación extendida utilizada (ej: Windows-1252, ISO-8859-1). No existe un estándar único.
- ¿Por qué es preferible Unicode a ASCII para textos con acentos? Unicode ofrece una representación universal y consistente de caracteres, evitando problemas de compatibilidad.
- ¿Qué sucede si se usa una codificación ASCII incorrecta para un texto con minúsculas acentuadas? El texto puede mostrarse con caracteres incorrectos o símbolos extraños.
Conclusión
Si bien ASCII ha sido un estándar importante en la historia de la computación, sus limitaciones en la representación de caracteres internacionales, especialmente minúsculas acentuadas, han llevado a la adopción generalizada de Unicode. Unicode proporciona una solución más robusta y universal para la codificación de textos en diferentes idiomas, garantizando la correcta visualización y el intercambio de información sin problemas de compatibilidad.
Entender la diferencia entre ASCII y Unicode es fundamental para cualquier persona que trabaje con texto digital, ya sea para desarrollo web, procesamiento de datos o cualquier otra tarea que involucre la manipulación de caracteres.